Owners of websites that remained frozen for a year or more, because the _projects _they represent also were closed, or greatly slowed down their activity, face a big problem when those projects restart: updating the website without losing all its old content is really, really hard, if not impossible. Here is how I faced this problem with an old Drupal website, with an approach that can work on many other websites running off some database.
If a project restarts after one year or more, you must first of all update the content management system of its website to the now current version (and if you decide to change CMS, the tricks below are even more needed!). First of all, software that has security flaws so old should not run on the Internet, should it now? Besides, you will surely want at least some features that only are in the latest version. So you decide to upgrade the software, and reality hits you:
your CMS is now so old that (assuming it still works without any problem, with the current version of the server that hosts it!) upgrading it to its current version is a really time-consuming, completely undocumented process, with very little guarantees that it will result in a working website.
Free online support? Forget it, even if you are using, as you should, Free Software: in situations like these, the chances that you can find somebody who still remembers the problems you’ll face, or can reproduce them to help you are almost null. And it’s not theirs, or Free Software’ fault, of course!
Drupal is particularly bad from this point of view. It’s a great CMS, but it practically demands that you update from one incremental version to the very next, without ever jumping one version, if you want to avoid problems. Especially if you have more than ZERO non-core modules installed.
In addition to these purely technical problems, there are the “management” ones: if you restart a project after a long stop, it is very likely that both its structure, and the one of the website that must reflect it, will be quite different from the original one. In other words, you would have to discard, rewrite and rearrange a lot of content anyway, regardless of software updates pains.
Restart from the sources, and from those alone
For all the reasons above, the last time I found myself in this situation, that is with the website of the Free Technology Academy and Free Knowledge Institute, I suggested and implemented the radical approach below. Thanks to it, we are not 100% done with those two websites yet, but we are getting there in a way that is taking very little time off other activities, and above all gave us an up to date, as secure as can be websites from day one. The “radical approach” consists of:
- Forget about making static mirrors of the old website with wget and similar tools. First, they only work IF the website still runs properly. Third, they may NEVER end (in our case, wget would have continued to follow and download the “next month” calendar page till year 999999…). Third they would produce a huge quantity of stuff, like menus, blocks and other widgets that are totally useless in the new website
- make a complete plain-text backup of the old website with mysqldump
- put the old website offline, and** good riddance to it**
- redesign the whole website **from scratch, **with a structure that matches the **current **organization, priorities, activities, etc (but includes an archive section for all the old content that deserves to remain online!) using all the current features of Drupal (but we could have even chosen to switch CMS, no problem!)
- Install Drupal or whatever the new CMS is from scratch, and configure it as decided in step 4
- find in the file of the database dump the table(s) that stores the metadata and the actual content of all the Web pages that the old version of Drupal managed. This is important: “actual content” means just that, without all the boxes, site menus and other widgets that you couldn’t care less about, in a new website
- use scripts like the two ones below to save only those two tables in a separate text file and, respectively, read that text file, and save the HTML content of each node in a separate HTML file, named after the title and original publication date of that node
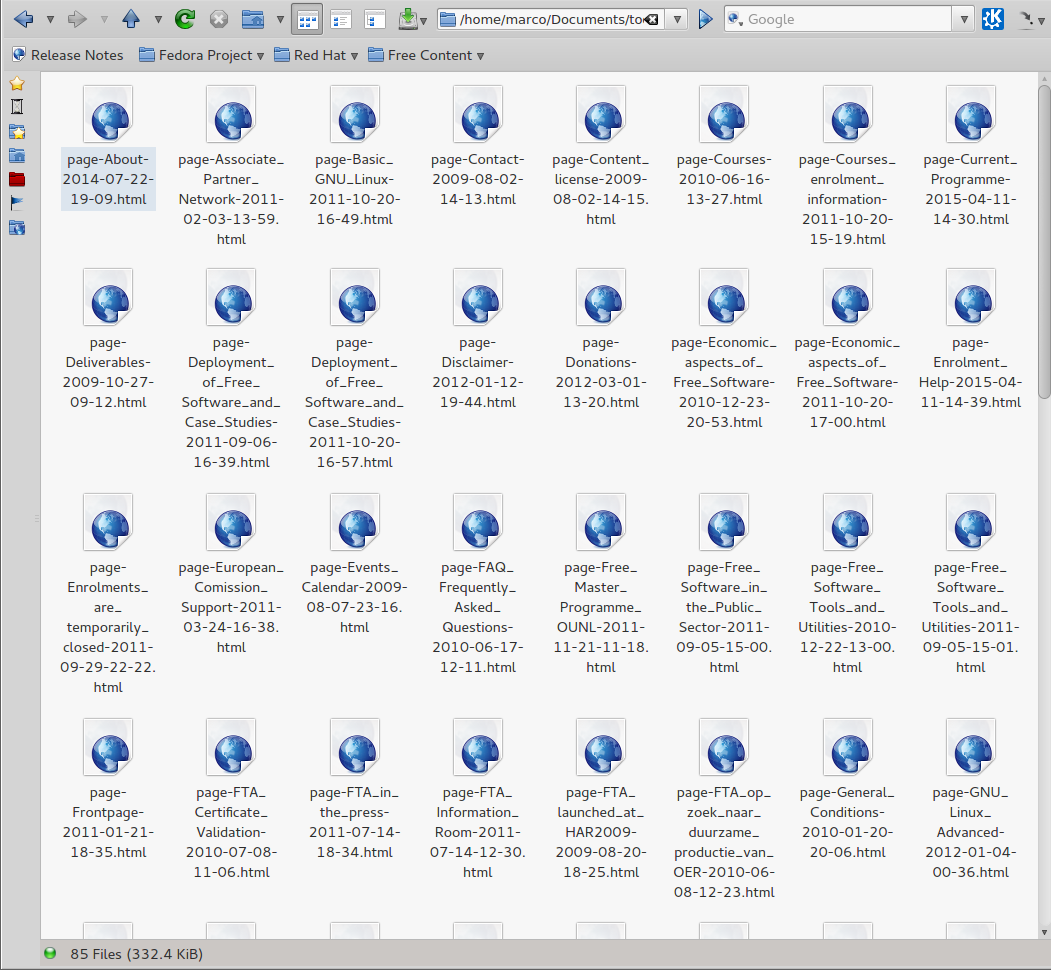
The whole procedure will leave you with a folder like the one in this screenshot: each page is in a separate file, so you can open it, copy and paste its content, or only the parts that are still current, in the proper place of the new website. Believe me, this is much more efficient than trying to rescue and transform the old one!
Important: the two scripts below are not examples of good Perl programming and best practices by any means! They were never meant to be, and they did not need to! This is just cut-n-paste code put together in a hurry, to run just once, without thinking to optimization, robustness and so on. Still, it worked and saved us a LOT of time, so it’s useful to share it as an example of how to proceed in similar situations. You’re welcome to post better versions, or versions for other CMSes, in the comments. Ditto for any other question you may have about it.
#! /usr/bin/perl
use strict;
# extract all and only the node* tables
my $PRINT = 'n';</code>
while (<>) {
$PRINT = 'y' if ($_ =~ m/^CREATE TABLE `node`/);
$PRINT = 'n' if ($_ =~ m/^CREATE TABLE `performance_detail`/);
print "$_" if ('y' eq $PRINT);
}
Second script:
#! /usr/bin/perl
use strict;
# extract all and only the node* tables</code>
my %nodes;
while (<>) {
if (m/^INSERT INTO `node`/) {
#INSERT INTO `node` VALUES (1,1,'page','','Main page'
s/^INSERT INTO `node` VALUES \(//;
my ($id, $v, $type, $title, $dummy) = split /,/;
$title =~ s/^'//; $title =~ s/'$//;
$nodes{$id}{'version'} = $v;
$_ =~ m/^\d+,\d+,'(.*?)','/ ; $nodes{$id}{'type'} = $1;
$_ =~ m/^\d+,\d+,'(.*?)','','(.*?)',/ ; $nodes{$id}{'title'} = $2;
#printf "NODE FOUND: %4.4s\t%4.4s\t%-15.15s\tT: %s;\n", $id, $v, $nodes{$id}{'type'}, $nodes{$id}{'title'};
}
if (m/^INSERT INTO `node_revisions`/) {
#INSERT INTO `node_revisions` VALUES (2,2,3,'About','
my ($id, $v, $title, $body, $timestamp);
$_ =~ m/VALUES \((\d+)/ ; $id = $1;
$_ =~ m/VALUES \(\d+,(\d+)/ ; $v = $1;
$_ =~ m/VALUES \(\d+,\d+,\d+,'(.*?)','/ ; $title = $1;
$_ =~ m/VALUES \(\d+,\d+,\d+,'(.*?)','(.*?)','/ ; $body = $2;
$_ =~ m/,(\d+),\d+\);$/; $timestamp = $1;
my ($sec,$min,$hour,$mday,$mon,$year,$wday,$yday,$isdst) = localtime($timestamp);
$year += 1900;
$mon++; $mon = "0$mon" if ($mon < 10);
$mday = "0$mday" if ($mday < 10);
$min = "0$min" if ($min < 10);
$hour = "0$hour" if ($hour < 10); my $date = "$year-$mon-$mday-$hour-$min"; $body =~ s/\\r\\n/\n/g; $body =~ s/\\'/'/g; $body =~ s/\\"/"/g; my $url = $title; $url =~ s/\W/_/g; $url =~ s/_+/_/g; $url =~ s/^_+//; $url =~ s/_+$//; my $filename = $url; $filename = "$nodes{$id}{'type'}-$filename-$date.html"; if ($nodes{$id}{'version'} == $v) { #printf "Found active version of %20.20s: $date\t%s;\n\n$body\n\n#########################\n\n", $nodes{$id}{'type'}, $title; #printf "Found active version of %20.20s: $date\t\t%s;\n", $nodes{$id}{'type'}, $title; printf "Saving active version of:\t%-60.60s into $filename;\n", $title; open(NODE, "> fta-content/$nodes{$id}{'type'}/$filename") || die "Cannot open NODE!\n";
print NODE "$nodes{$id}{'type'}: $title --- DATE: $date
<h1>$nodes{$id}{'type'}: $title --- DATE: $date</h1>
$body
";
close NODE;
}
}
}