Many people write far more now that they are constantly online than in the pre-Internet age. Most of this activity is limited to Web or office-style publishing. People either write something that will only appear inside some Web browser or a traditional “document”, that is a single file, more or less nicely formatted for printing. Very often, however, they don’t do it in the most efficient way.
The most common solution for the first scenario still is to write HTML or Wiki-formatted content in a text editor or, through a browser, directly in the authoring interface of CMS systems like Drupal or Wordpress. The other approach is even closer to the typewriting era, since it’s limited to using a word processor like OpenOffice. Both methods involve too much manual work for my taste, especially if you often want to reuse or move content from one format to the other.
Since I write a lot for both of the scenarios above and some more, some time ago I realized that I needed a more efficient and flexible workflow: something that was as close as possible to “write ONCE, publish anywhere, re-mixing and processing already written stuff in any possible way without getting mad along the way”. I wanted to write QUICKLY, without thinking at all of where or in which format the text would end up, while being prepared for all cases, from blog to book. I also wanted to use only Free Software that would run quickly even on old computers, with little or no configuration, if necessary on any operating system. Finally, I wanted the possibility to manage, search and process all my writings automatically, with command line utilities or shell scripts.
While I must admit I’m not there yet (especially when working on commission with very particular requirements) I already am pretty close to it in most cases. The rest of this article explains which software I chose and some scripts I wrote to work in this way, that is to write stuff only once and then convert it to a publishing-quality PDF or to HTML with just a few commands.
The first (easy) choice I had to make was “which file format should I use?”. I am a huge fan of the OpenDocument format (ODF), also because ODF is very easy to hack. However, the requirements above immediately exclude it as a source format for most of the stuff I write. The natural Free as in Freedom format for producing good PDF is still TeX or LaTeX, but I wanted HTML and OpenDocument as final options, which aren’t easy to obtain starting from TeX. Besides, I wanted to write quickly text that would be already highly readable in its native format, without too much markup in the way. The obvious conclusion was that I should write plain text marked up with a simple, wiki-like syntax as ReST, Markdown or txt2tags.
I chose the latter for two reasons. First, it has very good export to all formats I need (LaTeX, plain text, MediaWiki and HTML) with the exception of ODF which is, however, relatively easy to add, at least conceptually. Above all, however, txt2tags is simple. Its markup is very readable and easy to learn, but that’s not its biggest quality. 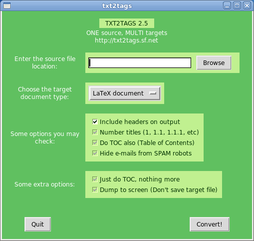
What I like is that the actual software consists of one small Python script that runs in a graphical interface (shown below) or at the prompt with a few options, without depending on any third party library or additional module. Unless your operating system doesn’t support Python, you only need to have that script and any text editor to work.
Sure, you need other software to generate PDF files from LaTeX, and auxiliary shell scripts for pre- and post-processing like what I describe below but (unlike what I found in other markup systems) that’s all Free Software that’s guaranteed to be already packaged in almost all Gnu/Linux distributions (including server-oriented ones, for automatic remote processing!) and also available for Windows. Besides, being a command line tool that can accept text from STDIN or send it to STDOUT, txt2tags integrates perfectly with any other script-based text processing procedure one may need.
Ultra-quick intro to txt2tags syntax pros and cons
The markup syntax of Txt2Tags (see its online demo) leaves the source text very readable. Headers have one or more equal signs at the beginning and end of the line. Numbered and non-numbered list items start with a dash or plus character. Hyperlinks are included in square brackets, asterisks delimitate bold text and slashes are for italic. To build tables you must enclose the content of each cell in pipe signs (|). Comments start with a percent and preprocessing directives with a negated comment (%!). The only two things I care about that txt2tags doesn’t support natively are footnotes and cross-references to tables and figures. For footnotes there’s one workaround in this tutorial and one in the txt2tags configuration file of S. D’Archino. Cross-references are (relatively speaking) much more complicated to add, but are still possible by generalizing the approach described in the final part of this article, if you really need them.
Click to read the How to transform (almost) plain ASCII text to Lulu-ready PDF files, part 2