This is the core script I used to transform a set of plain ASCII files with the Txt2tags markup in one print-ready PDF file. Part 1 of this tutorial explain why I chose txt2tags as source format and Part 2 describes the complete flow.
Book creation workflow
Listing 1: make_book.sh
1 #! /bin/bash
2
3 CONFIG_DIR='/home/marco/.ebook_config'
4 PREPROC="%!Includeconf: $CONFIG_DIR/txt2tags_preproc"
5
6 CURDIR=`date +%Y%m%d_%H%M_book`
7 echo "Generating book in $CURDIR"
8 rm -rf $CURDIR
9 mkdir $CURDIR
10 cp $1 $CURDIR/chapter_list
11 cd $CURDIR
12
13 FILELIST=`cat chapter_list | tr "�12" " " | perl -n -e "s/.//..//g; print"`
14
15 echo '' > source_tmp
16 echo $PREPROC >> source_tmp
17 sed 's/.//%!Include: .//g' $FILELIST >> source_tmp
18
19 replace_urls_with_refs.pl source_tmp > source_with_refs
20
21 txt2tags -t tex -i source_with_refs -o tex_source.tex
22 perl -pi.bak -e 's/OOPENSQUARE/[/g' tex_source.tex
23 perl -pi.bak -e 's/CLOOSESQUARE/]/g' tex_source.tex
24
25 #remove txt2tags header and footer
26 LINEE=`tail -n +8 tex_source.tex | wc -l`
27 LINEE_TESTO=`expr $LINEE - 4`
28 tail -n +8 tex_source.tex | head -n $LINEE_TESTO > stripped_source.tex
29
30 source custom_commands.sh
31
32 cat $CONFIG_DIR/header.tex stripped_source.tex $CONFIG_DIR/trailer.tex > complete_source.tex
33 pdflatex complete_source.tex
34 pdflatex complete_source.tex
35
36 # Generate URL list in HTML format
37 generate_url_list.pl chapter_list html | txt2tags -t xhtml -no-headers -i - -o url_list.html
All the txt2tags settings and some LaTeX templates are stored in the dedicated folder $CONFIG_DIR, so you can have a different configuration for each project. The scripts itself only takes one parameter, that is a list of all the source files that must be included in the book. Lines 6 to 12 create a work directory and copy the file list inside it. The files must be written in the file list with their absolute paths, in the order in which they must appear in the book.
Lines 13 to 17 of the script create a single source file (source_tmp) that contains the Include command loading all the txt2tags preprocessing directives (line 16) and then the content of all the individual files, in the right order but without the Include directives that are needed when processing them individually (line 17).
Line 19 runs a separate script, replace_urls_with_refs.pl, that adds the cross-reference numbers to the book text and dumps the result into another temporary file, source_with_refs. This script, not included here for brevity and because you can do without it if you don’t need cross-references like me, only does two things. First it reads a file in the $CONFIG_DIR folder that contains, one per line, all the URLs mentioned in the source files and the corresponding captions, in this format:
‘http://www.greenparty.org.uk/news/2851 | Windows Vista? A “landfill nightmare”
Next, replace_urls_with_refs.pl reads source_tmp and, whenever it finds a line like:
the UK Green Party officially declared Vista... a ["landfill nightmare" http://www.greenparty.org.uk/news/2851]
generates the right cross-reference number and puts it right after the text associated to the link itself, writing everything to source_with_refs. You can see the effect in the last figure of part 2 of this tutorial. After all this pre-processing, we can finally run txt2tags to produce a LaTeX file (line 21) but right after that we need to put back square brackets in place of some temporary markup generated by replace_urls_with_refs.pl (lines 22⁄23). The next part of the script, until line 32, remove the default LaTeX header and footer created by txt2tags, replaces them with those stored in the $CONFIG_DIR folder and dumps everything into complete_source.tex: this move allows you to declare whatever LaTeX class you wish to use (I used Memoir), or to give any other LaTeX instruction in the header, without any interference or involvement from txt2tags. 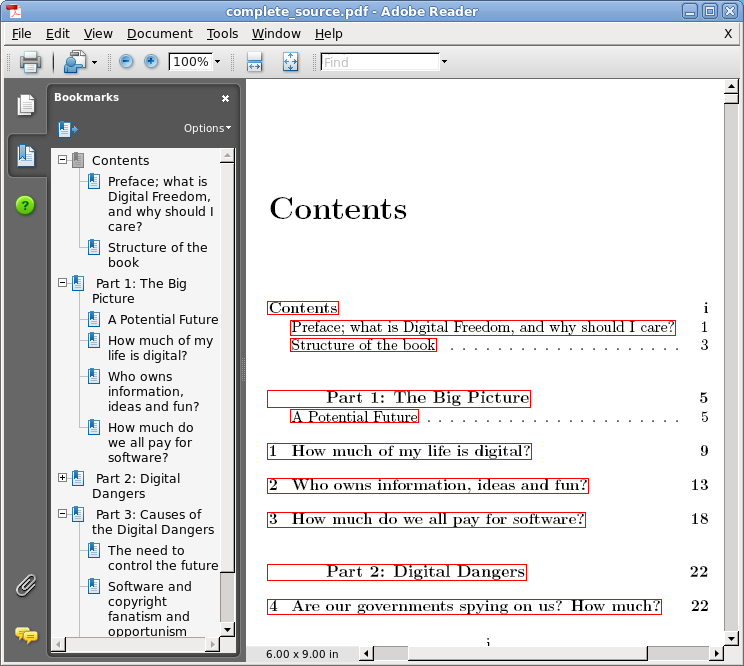
Sometimes I use line 30, also optional, to execute any other post-processing commands on the LaTeX source that, for any reason, it is not convenient to run before. The two invocations of pdflatex in lines 33⁄34 finish the job: the first creates a first draft of the book to calculate page numbers and other data, the second produces the final PDF with clickable table of contents (see below) and all the other goodies the Memoir LaTeX class can handle. The script in line 37 is the one that scans again all the source files to produce the HTML list of references.
Summing all up
I haven’t described all the gory details and auxiliary scripts at lenght because my main goal with this article is to introduce a txt2tags-based way of working. As I already said, this general method is quite simple but in spite of this, or maybe just for this reason, I find it very, very flexible and powerful. Two great Free Software applications, txt2tags and pdflatex, plus about one hundred lines of codes in three separate scripts, can produce print-ready digital books and/or all the HTML code you need to make an online version or simply an associated website. Besides, you can easily add to the mix programs like curl or ftp upload everything to a server. Personally, my next step will be to extend make_book.sh to generate OpenDocument files thanks to OpenDocument scripting.